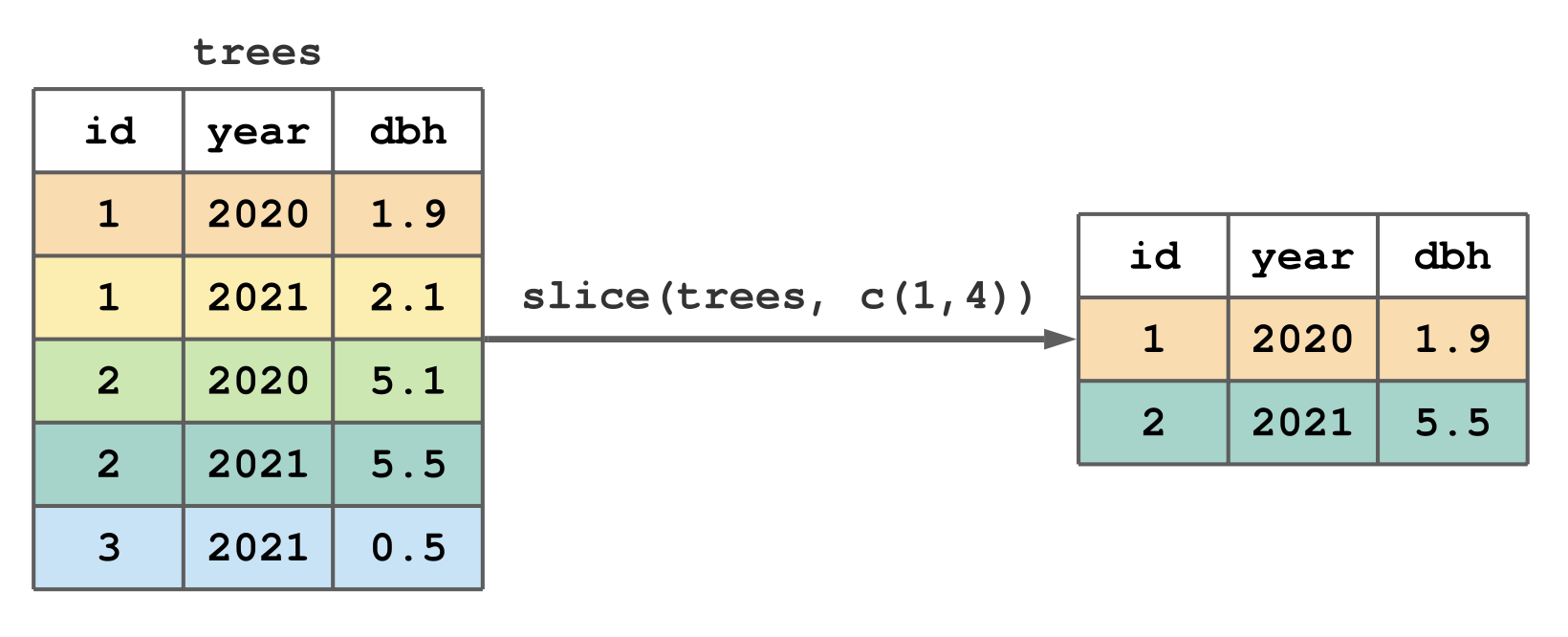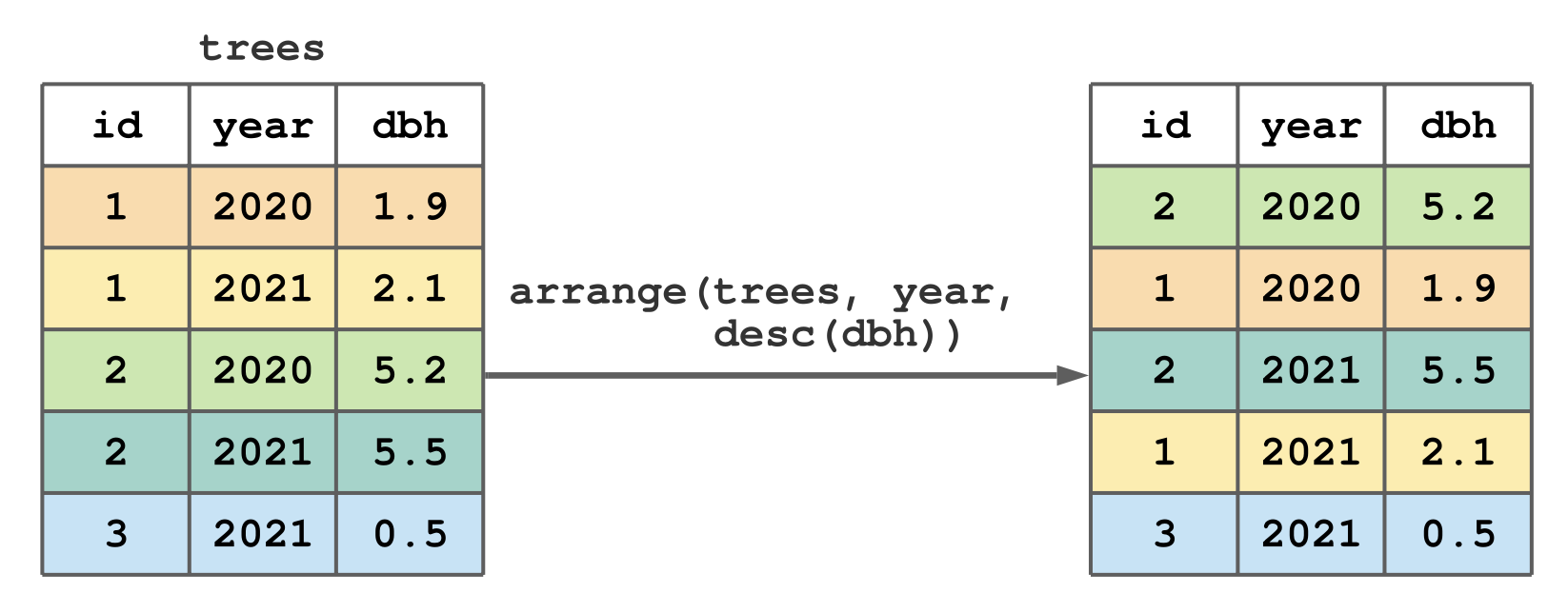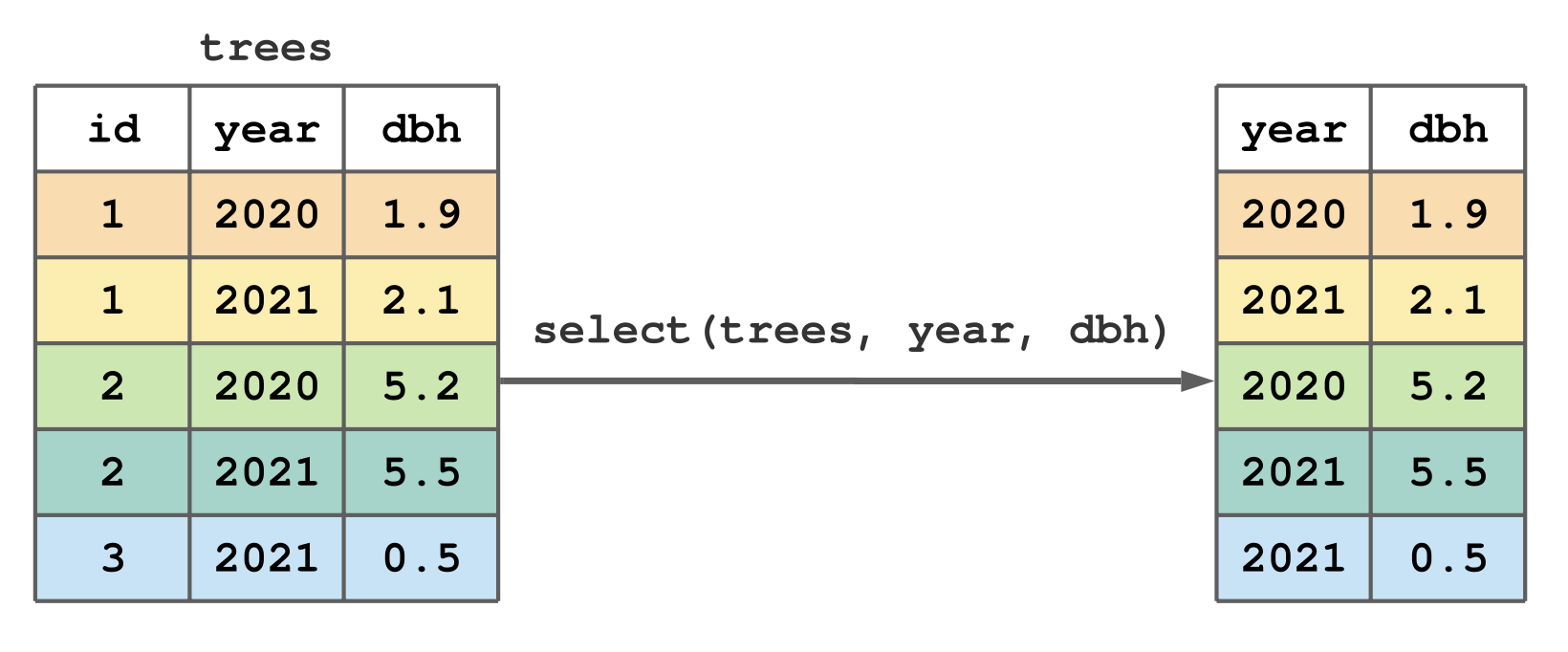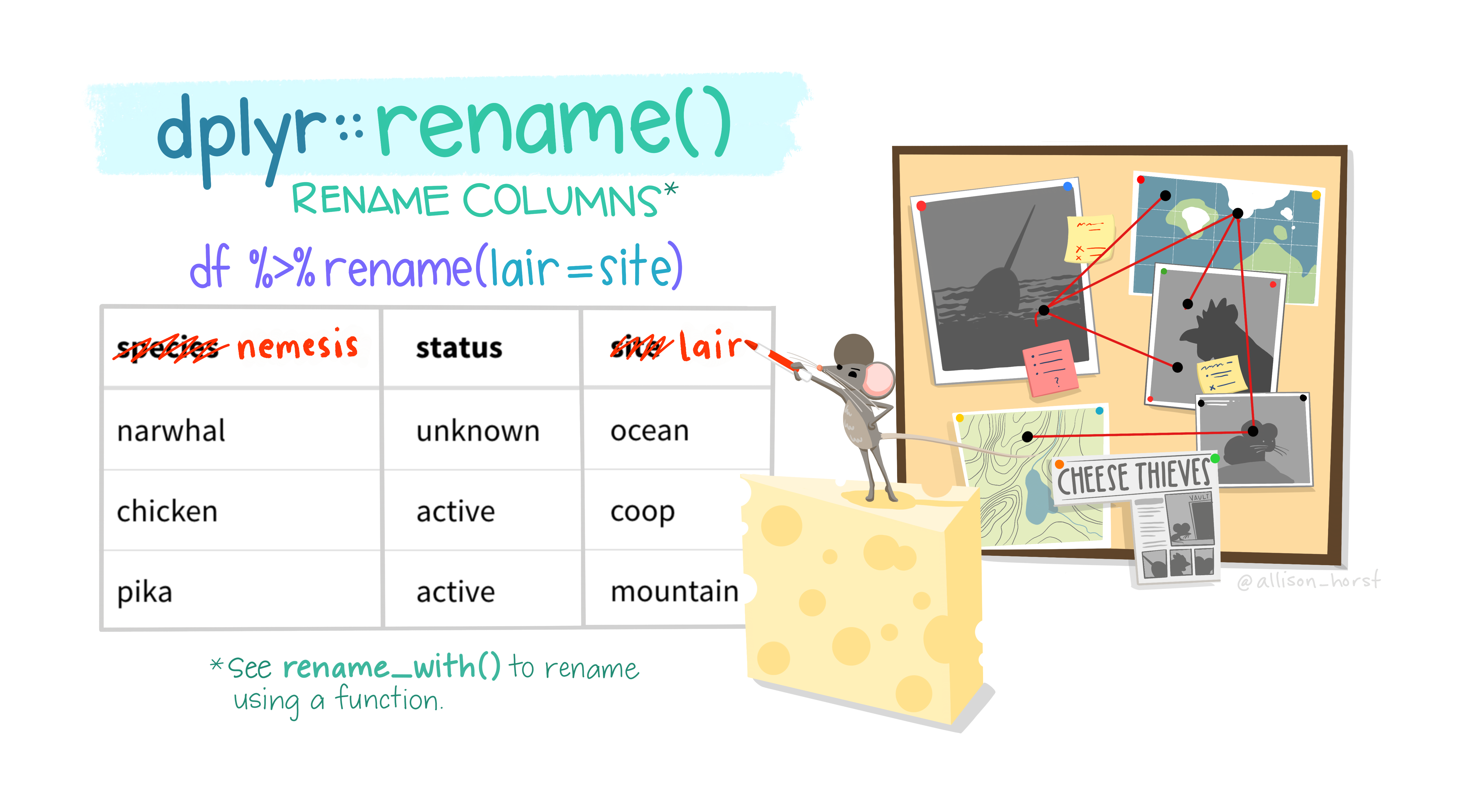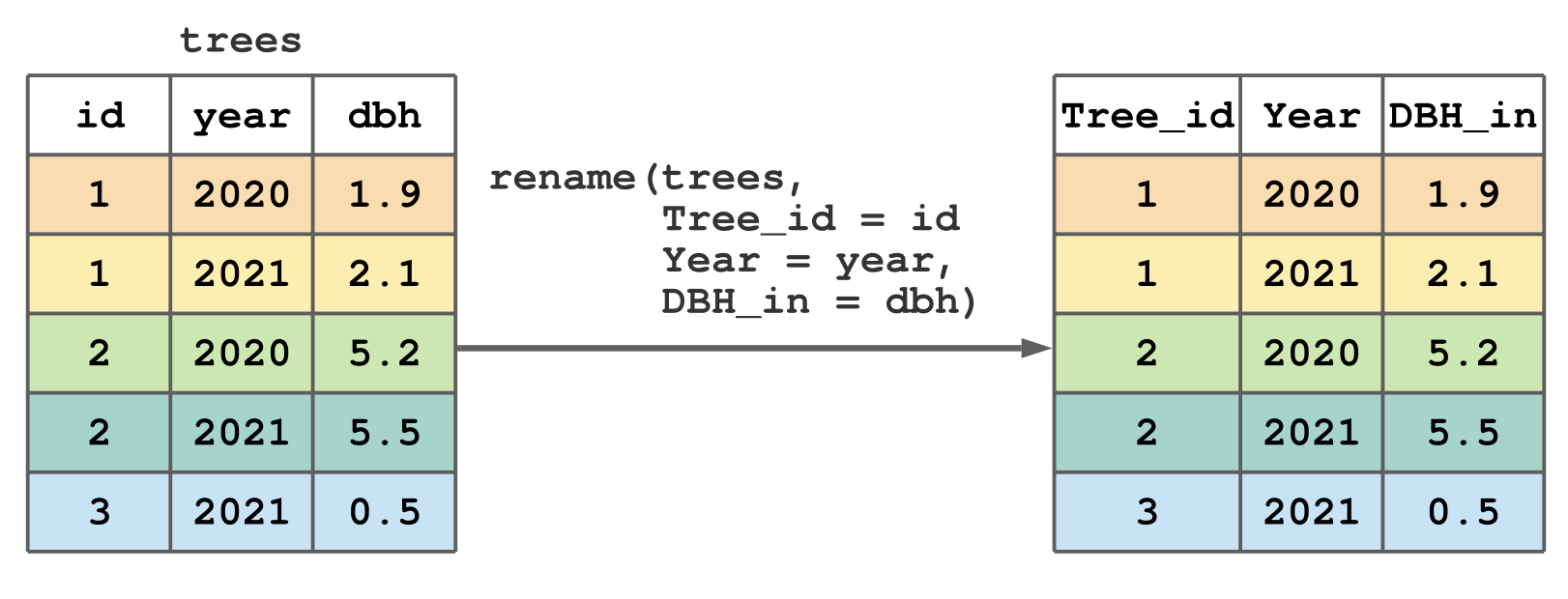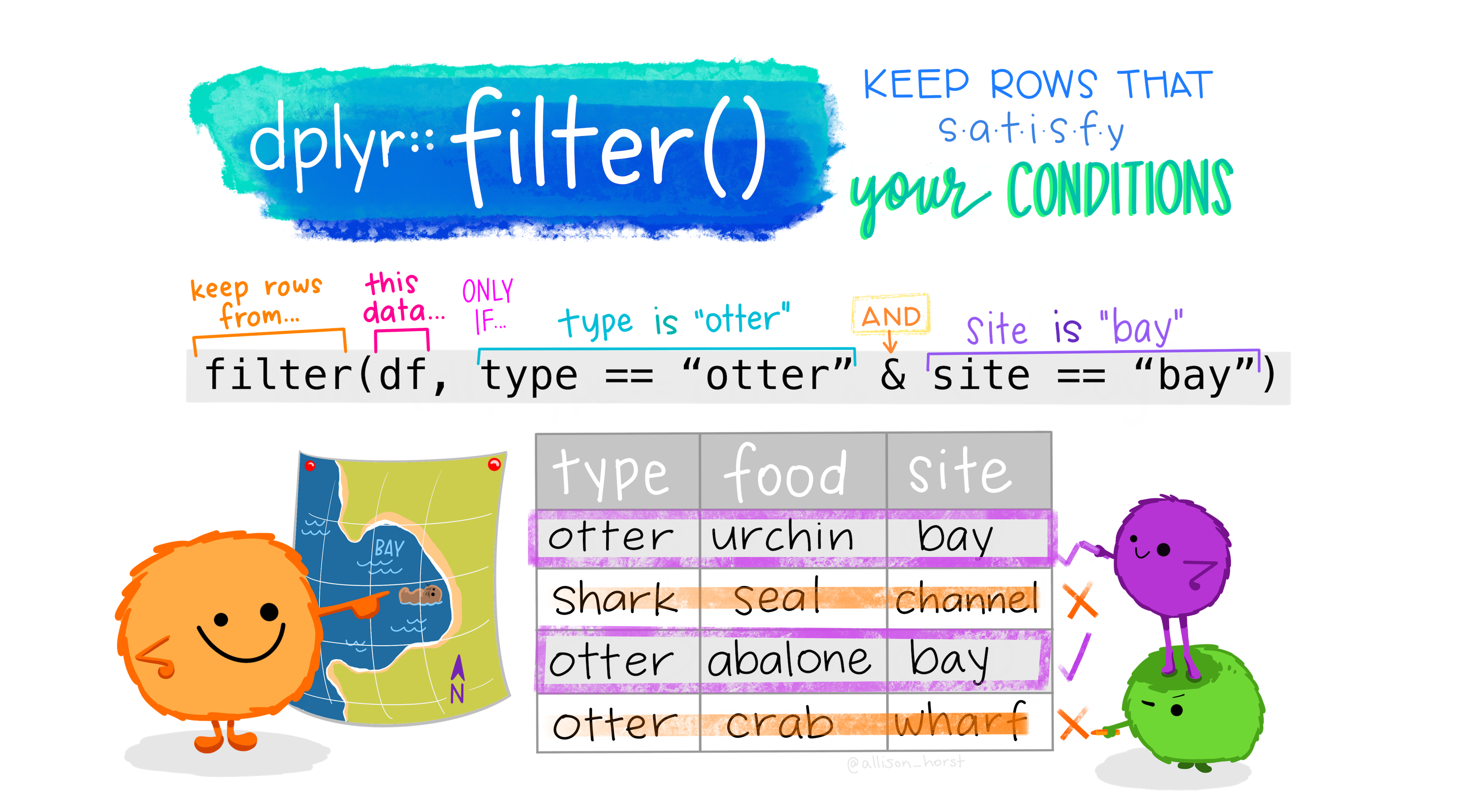
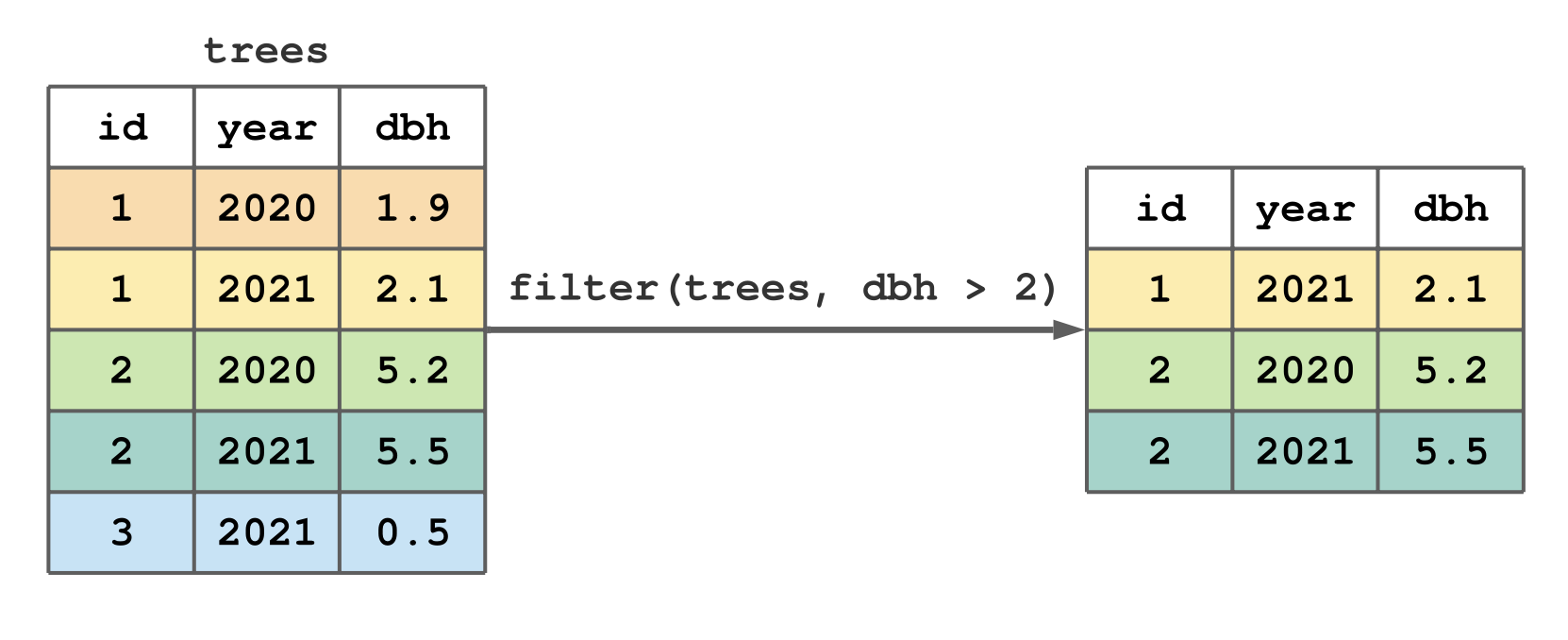
library(tidyverse)
pets <- tibble(
names = c("Dude", "Pickle", "Kyle", "Nubs"),
ages = c(6, 5, 3, 11),
is_dog = c(TRUE, FALSE, FALSE, FALSE)
)
pets# A tibble: 4 × 3
names ages is_dog
<chr> <dbl> <lgl>
1 Dude 6 TRUE
2 Pickle 5 FALSE
3 Kyle 3 FALSE
4 Nubs 11 FALSE